

Author:
(1) Sharif Elcott, equal contribution of Google Japan (Email: selcott@google.com);
(2) J.P. Lewis, equal contribution of Google Research USA (Email: jplewis@google.com);
(3) Nori Kanazawa, Google Research USA (Email: kanazawa@google.com);
(4) Christoph Bregler, Google Research USA (Email: bregler@google.com).
Table of Links
- Abstract and Introduction
- Background and Related Work
- Method
- Results and Failure Cases
- Limitations and Conclusion, Acknowledgements and References
2 BACKGROUND AND RELATED WORK
The alpha-compositing equation is
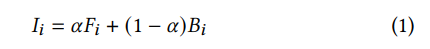
where 𝑖 ∈ {𝑟, 𝑔, 𝑏}, 𝐼𝑖 are red, green, and blue values at a pixel of the given image (given), 𝐹𝑖 are the foreground object color (unknown), 𝐵𝑖 are the background object color (unknown), and 𝛼 ∈ [0, 1] is the (partially unknown) "alpha matte", representing the translucency or partial coverage of the foreground object at the pixel.
Typical images contain large areas that are relatively easily estimated to be solid "foreground" (𝛼 = 1) or "background" (𝛼 = 0), as well as smaller regions where the alpha value is fractional. The matte extraction problem requires finding the these fractional alpha values. The problem is underconstrained because there are only three known values 𝐼𝑟, 𝐼𝑔, 𝐼𝑏 but seven unknown values. Hair is the prototypical challenge for matte extraction due to its irregular coverage and translucency, though fractional alpha also generally appears along all object edges due to the partial coverage of a pixel by the foreground object. It is also necessary to estimate the unknown foreground color in the fractional alpha regions, since without this the foreground cannot be composited over a different background. Many methods assume that approximate demarcations of the solid foreground and background are provided, e.g. in the form of artist-provided "trimaps" [Rhemann et al. 2009] or scribbles [Levin et al. 2008].
While the research literature generally considers the problem of matte extraction from arbitrary natural backgrounds, in industry practice matte extraction from a greenscreen background is far from a solved problem and often requires an artist-curated combination of techniques to obtain the required quality [Erofeev et al. 2015; Heitman 2020]. LED walls remove the need for greenscreens in some cases, and are well suited for fast-paced television production, however they also have drawbacks: computationally expensive physical or character simulations are not possible due to the need for real-time playback in a game engine, bright backgrounds may introduce challenging light spill on the foreground physical objects [Seymour 2020], their cost is prohibitive for smaller studios, and the effects must be finished at the time of the principle shoot thus excluding the creative control and iterative improvement available in traditional post production.
Progress on matte extraction algorithms has been greatly facilitated by datasets that include ground truth (GT) mattes [Erofeev et al. 2015; Rhemann et al. 2009]. The GT mattes have been obtained by different means including chroma keying from a greenscreen and photographing a representative toy object in front of a background image on a monitor (Fig. 1 (a)). Failure to closely approximate these GT mattes indicates a poor algorithm, but an exact match may be unobtainable for several reasons: 1) the chroma key itself involves an imperfect algorithm [Erofeev et al. 2015], 2) light from multiple locations can physically scatter though (e.g.) translucent hair to arrive at a single pixel; this cannot be simulated in a purely 2D matte extraction process, 3) the image gamma or color space used in the benchmarks is not always evident and using a different gamma will produce small differences.
The underconstrained nature of matte extraction has been approached with a variety of methods [Wang and Cohen 2007]. One classic approach estimates the unknown alpha at a pixel based on similarity to the distributions of known foreground and background colors in solid regions [He et al. 2011; Mishima 1992]. Another prominent principle finds the unknown alpha value by propagating from surrounding known values [Aksoy et al. 2018; Levin et al. 2008]. These approaches often require solving a system involving a generalized Laplacian formed from the pixel affinities in the unknown region, which prevents real-time or interactive use.
Deep learning (DL) approaches are used in recent research e.g. [Lin et al. 2020; Sun et al. 2021]. Much of this work focuses on providing alternate backgrounds for video meetings, and training databases consist of mostly forward-facing human heads. A state of the art method [Lin et al. 2020] demonstrates high-quality matte extraction on HD-resolution images at 60fps. Many DL methods adopt a combination of techniques, e.g. separate networks for overall segmentation and for fractional alpha regions, or other hybrid approaches.

2.1 Deep Image Prior
The Deep Image Prior (DIP) [Ulyanov et al. 2018] demonstrates that the architecture of an untrained convolutional network provides a surprisingly good prior for tasks such as image inpainting and denoising. The key observation is that while a powerful DNN can fit arbitrary image structures such as noise, it is "easier" to fit natural image structures, as reflected in faster loss curve decay. Most experiments [Ulyanov et al. 2018] optimize the weights of a U-net [Ronneberger et al. 2015] that maps fixed random noise to a single output image. Uncorrupted features of the image are fit earlier in the optimization process, so early stopping results in a corrected (denoised or inpainted) image.
The DIP has been successfully applied to other problems in image processing. Unsupervised coarse binary segmentation is demonstrated in [Gandelsman et al. 2019], based on a principle that it is easier (in terms of loss decay) to fit each component of a mixture of images with a separate DIP rather than using a single model. Concurrent with our work, [Xu et al. 2022] formulate a DIP approach to background matting. This problem scenario differs from our work in that it requires a clean plate, and hence is unsuitable for many VFX applications such as those that are filmed outdoors with a moving camera.
Our work also uses the DIP. We focus on high-quality estimation of fractional alpha mattes and, in contrast to previous work, undertake the challenging case where no clean plate is available, instead relying only on trimaps that can be easily created during post-production.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.