

What Is Steganography?
Imagine you want to send a secret message to a friend, but the channel you want to use is compromised and monitored. You could use some encryption, but that would arouse the suspicion of the people monitoring your conversations, so you'd have to use something else.
Nowadays, steganography is a method of hiding secret messages in another, non-secret file (like a picture of a cat), so that if you sent that file, it would not be detected. Steganography is not limited to hiding text in images and generally means "hiding secret information in another non-secret message or physical object": you can hide some messages in audio, video, or other texts using, for example, columnar transposition.
Steganography can also be extremely useful in many other cases, for example, it can be a good alternative to watermarking in sensitive documents to protect them against leakage.
There are many ways to hide information in images, from simply appending the text at the end of the file to hiding it in the metadata. In this article, I want to cover a more advanced method of steganography, going down to the binary level and hiding messages within the boundaries of the image itself.
Building a Steganographic Engine
The UI
For my example of steganography, I decided to use JavaScript because it is a powerful programming language that can be executed in a browser.
I've come up with a simple interface that allows users to upload an image to read the hidden message in it, or to encode a message in an image themselves.
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Steganography</title>
<style>
body {
font-family: Arial, sans-serif;
text-align: center;
margin-top: 50px;
}
textarea {
width: 300px;
height: 100px;
}
button {
margin: 10px;
}
#outputImage {
margin-top: 20px;
max-width: 100%;
}
</style>
</head>
<body>
<h1>Steganography Example</h1>
<input type="file" id="upload" accept="image/*"><br>
<canvas id="canvas" style="display:none;"></canvas><br>
<textarea id="text" placeholder="Enter text to encode"></textarea><br>
<button id="encode">Encode Text</button>
<button id="decode">Decode Text</button>
<p id="decodedText"></p>
<img id="outputImage" alt="Output Image">
<script src="./script.js"></script>
</body>
</html>
To use it, users can simply select an image they want to manipulate and either try to decode some text from it, or encode it and download the image later.
Processing Images
To work with images in JavaScript, we can use the Canvas API. It provides many different functions for manipulating and drawing images, animations, or even game graphics and videos.
Canvas API is primarily used for 2D graphics. If you want to work with 3D, hardware-accelerated graphics, you can use the WebGL API (which, incidentally, also uses the <canvas> element).
const canvas = document.getElementById("canvas");
const ctx = canvas.getContext("2d");
const image = new Image();
To read the image file from the file system and add it to the canvas context, we can use the FileReader API. It allows us to easily read the contents of any file stored on the user's computer without the need for a custom library.
function handleFileUpload(event) {
const reader = new FileReader();
reader.onload = function (e) {
image.src = e.target.result;
image.onload = function () {
canvas.width = image.width;
canvas.height = image.height;
ctx.drawImage(image, 0, 0);
};
};
reader.readAsDataURL(event.target.files[0]);
}
It reads a file and draws the image in that file onto our previously defined 2D canvas context, after which, we can either encode some text into that image or try to read the text from the image.
Hiding Text in Images
Images are made up of pixels, and each pixel contains information about its colors. For example, if an image is encoded using the RGBA model, each pixel would contain 4 bytes of information about how much red, green, blue, and alpha (opacity) it represents.
To encode some text in an image, we could use one of these channels (for example, the alpha channel). As this information is represented in the binary system (like 01001100), we could switch the last bit to whatever we need. It's called the Least Significant Bit (LSB), and changing it causes minimal change to the image itself, making it indistinguishable from a human.
Now, imagine we have text like "Hello" and we want to encode it into an image. The algorithm to do this would be
-
Convert "Hello" text to binary.
-
Iterate through the bytes of image data, and replace the LSB of those bytes with a bit from the binary text (each pixel contains 4 bytes of data for each of the colors, in my example, I want to change the opacity channel of the image, so I would iterate on every 4th byte).
-
Add a null byte at the end of the message so that when decoding, we know when to stop.
-
Apply modified image bytes to the image itself.
First, we need to take the text we want to encode from the user and perform some basic validations on it.
const text = document.getElementById("text").value;
if (!text) {
alert("Please enter some text to encode.");
return;
}
Then, we need to convert the text to binary and create a canvas of the image we're going to encode this text into.
const imgData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const data = imgData.data;
let binaryText = "";
for (let i = 0; i < text.length; i++) {
let binaryChar = text.charCodeAt(i).toString(2).padStart(8, "0");
binaryText += binaryChar;
}
To do this, we can simply iterate over each of the characters and get a Unicode index using the charCodeAt function. This Unicode is then converted to binary and padded so that it is the same length as any other character.
For example, the letter "H" is represented as 72 in Unicode; we then convert this number to binary (1001000), and add 0s at the beginning (01001000) to make sure that all the letters would be the same length (8 bits).
Then, we need to add a null byte at the end of the message to make sure that when we decrypt it, we can distinguish between the real text and the random pixel data of the image.
binaryText += "00000000";
Then, we need to do some basic validation to make sure that the image has enough pixels to encode our message so that it does not overflow.
if (binaryText.length > data.length / 4) {
alert("Text is too long to encode in this image.");
return;
}
And then comes the most interesting part, the encoding of the message. The data array we defined earlier contains pixel information in the form of RGBA values for each pixel in the image. So, if the image is RGBA encoded, each pixel in it would be represented by 4 values of the data array; each value representing how much red, green, and blue that pixel has.
for (let i = 0; i < binaryText.length; i++) {
data[i * 4] = (data[i * 4] & 0b11111110) | parseInt(binaryText[i]);
}
ctx.putImageData(imgData, 0, 0);
const outputImage = document.getElementById("outputImage");
outputImage.src = canvas.toDataURL();
In the code above, we iterate over our binary-encoded text. data[i * 4] finds a byte that we need to modify, and since we only want to modify the bytes of a particular channel, we multiply the variable i by 4 to access it.
The data[i * 4] & 0b11111110 operation sets the least significant bit to 0. For example, if data[i * 4] is 10101101 in binary, then the 10101101 & 11111110 operation results in 10101100. This ensures that the LSB is set to 0 before we do any further manipulation with it.
The parseInt(binaryText[i]) is a current bit from the binary encoded string; it is either 1 or 0. We can then set this bit to the LSB using a bitwise OR (|) operation. For example, if the left part of the bitwise OR is 10101100 and the binaryText[i] is 1, then 10101100 | 00000001 would result in 10101101. If the current bit were 0, then the OR would result in 10101100. This is why we had to delete the LSB in the first place.
Once the message is encoded, we can place it in the current canvas and render it in HTML using the canvas.toDataURL method.
Decoding Hidden Messages From Images
The process of decoding an image is actually much simpler than encoding. Since we already know that we have only encoded the alpha channel, we can simply iterate over every 4th byte, read the last bit, concatenate it into our final string, and convert this data from binary into a Unicode string.
First, we need to initialize the variables. Since imgData is already populated with the image information (we call ctx.drawImage every time we read a file from the file system), we can simply extract it into the data variable.
const imgData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const data = imgData.data;
let binaryText = "";
let decodedText = "";
Then we need to iterate over every 4th byte of the image, read the last bit, and concatenate it to the binaryText variable.
for (let i = 0; i < data.length; i += 4) {
binaryText += (data[i] & 1).toString();
}
data[i] is the encoded byte, and to extract the LSB, we can use the bitwise AND (&) operator. It takes two values and performs an AND operation on each pair of corresponding bits. By comparing data[i] with 1, we basically isolate the least significant bit from the pixel information, and if the LSB is 1, then the result of such an operation is 1. If the LSB is 0, the result would also be 0.
Once we have read all the LSBs and stored them in the binaryText variable, we need to convert it from binary to plain text. Since we know that each character consists of 8 bits (remember how we used padStart(8, "0") to make each character the same length?), we can iterate on every 8th character of the binaryText.
Then we can use the .slice() operation to extract the current byte from the binaryText based on our iteration. The binary string can be converted to a number using parseInt(byte, 2) function.
Then we can check if the result is 0 (a null byte) - we stop the conversion and query the result. Otherwise, we can find which character corresponds to the Unicode number and add it to our result string.
for (let i = 0; i < binaryText.length; i += 8) {
let byte = binaryText.slice(i, i + 8);
if (byte.length < 8) break; // Stop if the byte is incomplete
let charCode = parseInt(byte, 2);
if (charCode === 0) break; // Stop if we hit a null character
decodedText += String.fromCharCode(charCode);
}
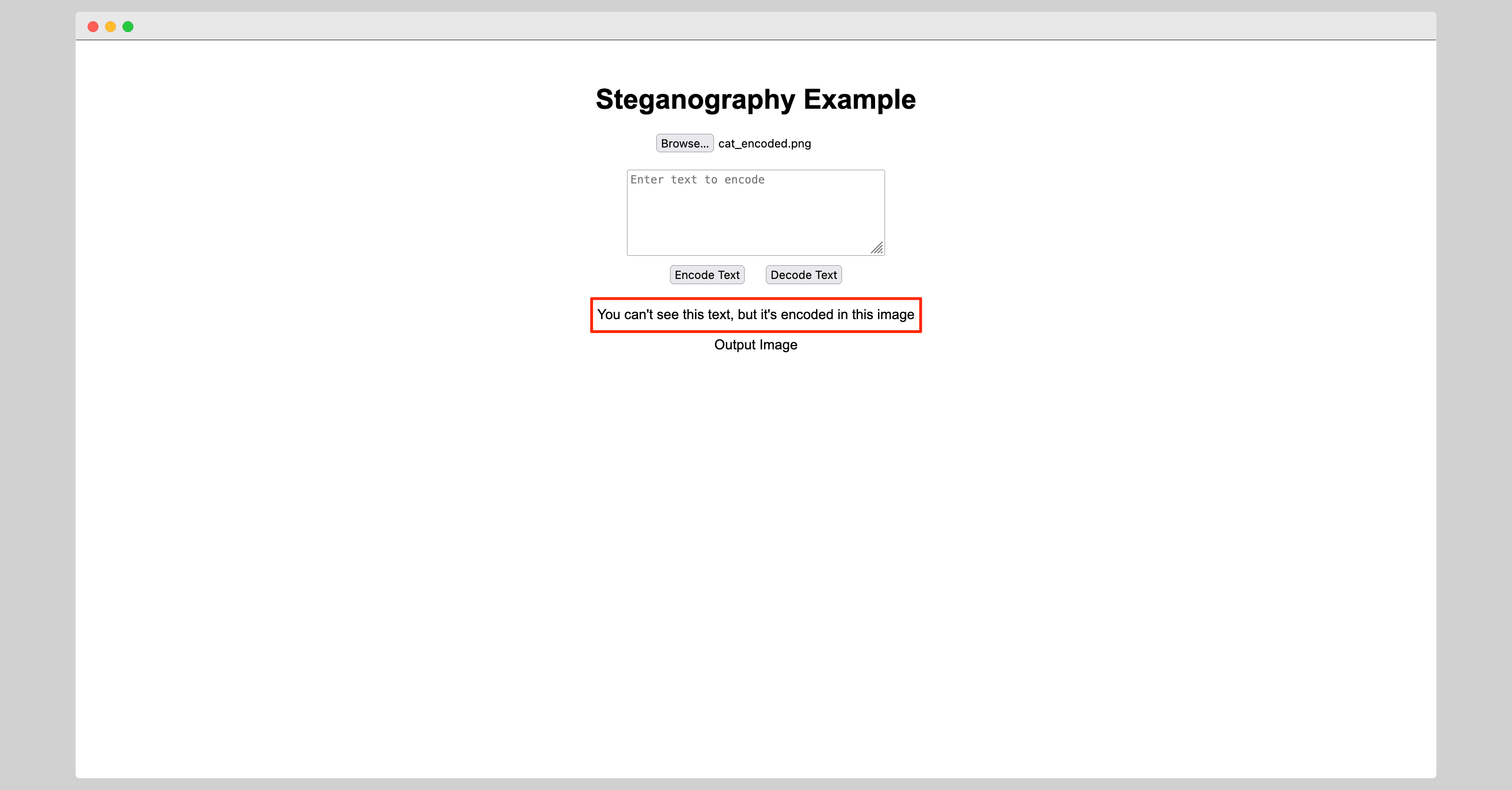
The decoded text can then be safely displayed to a user:
document.getElementById("decodedText").textContent = decodedText;
I’ve left the full code used in this article in my GitHub repository; feel free to play around with it. There are lots of things that could be improved :)
Final Thoughts
Steganography is a very powerful technique, and it can be applied to a lot of different use cases, starting from document verification, leak prevention, image AI verification, music file DRM management, and many more. This technique can even be applied to videos, games, or even raw text, so I think it has huge potential.
In the era of NFTs and blockchains, it's even more interesting to see how it will find its use cases and how this technique will evolve.