

Authors:
(1) Keivan Alizadeh;
(2) Iman Mirzadeh, Major Contribution;
(3) Dmitry Belenko, Major Contribution;
(4) S. Karen Khatamifard;
(5) Minsik Cho;
(6) Carlo C Del Mundo;
(7) Mohammad Rastegari;
(8) Mehrdad Farajtabar.
Table of Links
2. Flash Memory & LLM Inference and 2.1 Bandwidth and Energy Constraints
3.2 Improving Transfer Throughput with Increased Chunk Sizes
3.3 Optimized Data Management in DRAM
4.1 Results for OPT 6.7B Model
4.2 Results for Falcon 7B Model
6 Conclusion and Discussion, Acknowledgements and References
4.1 Results for OPT 6.7B Model
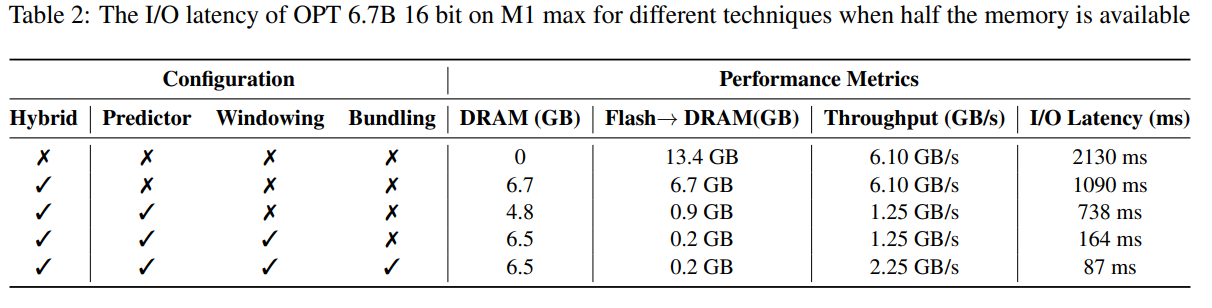
This section presents the outcomes for the OPT 6.7B model, specifically under conditions where the memory allocated for the model in DRAM is approximately half of its baseline requirement.

Windowing in the OPT 6.7B Model. Utilizing a windowing method with k = 5 in the OPT 6.7B model significantly reduces the necessity for fresh data loading. Using active neurons of predictor would require about 10% of the DRAM memory capacity in average; however, with our method, it drops to 2.4%. This process involves reserving DRAM memory for a window of the past 5 tokens, which, in turn, increases the DRAM requirement for the Feed Forward Network (FFN) to 24%.
The overall memory retained in DRAM for the model comprises several components: Embeddings, the Attention Model, the Predictor, and the Loaded Feed Forward layer. The Predictor accounts for 1.25% of the model size, while Embeddings constitute 3%. The Attention Model’s weights make up 32.3%, and the FFN occupies 15.5% (calculated as 0.24×64.62). Summing these up, the total DRAM memory usage amounts to 52.1% of the model’s size.
Latency Analysis: Using a window size of 5, each token requires access to 2.4% of the Feed Forward Network (FFN) neurons. For a 32-bit model, the data chunk size per read is 2dmodel × 4 bytes = 32 KiB, as it involves concatenated rows and columns. On an M1 Max, this results in the average latency of 125ms per token for loading from flash and 65ms for memory management (involving neuron deletion and addition). Thus, the total memory-related latency is less than 190ms per token (refer to Figure 1). In contrast, the baseline approach, which requires loading 13.4GB of data at a speed of 6.1GB/s, leads to a latency of approximately 2330ms per token. Therefore, our method represents a substantial improvement over the baseline.
For a 16-bit model on a GPU machine, the flash load time is reduced to 40.5ms, and memory management takes 40ms, slightly higher due to the additional overhead of transferring data from CPU to GPU. Nevertheless, the baseline method’s I/O time remains above 2000 milliseconds.
Detailed comparisons of how each method impacts performance are provided in Table 2.
Table 2: The I/O latency of OPT 6.7B 16 bit on M1 max for different techniques when half the memory is available
This paper is available on arxiv under CC BY-SA 4.0 DEED license.