

Authors:
(1) Mingjie Liu, NVIDIA {Equal contribution};
(2) Teodor-Dumitru Ene, NVIDIA {Equal contribution};
(3) Robert Kirby, NVIDIA {Equal contribution};
(4) Chris Cheng, NVIDIA {Equal contribution};
(5) Nathaniel Pinckney, NVIDIA {Equal contribution};
(6) Rongjian Liang, NVIDIA {Equal contribution};
(7) Jonah Alben, NVIDIA;
(8) Himyanshu Anand, NVIDIA;
(9) Sanmitra Banerjee, NVIDIA;
(10) Ismet Bayraktaroglu, NVIDIA;
(11) Bonita Bhaskaran, NVIDIA;
(12) Bryan Catanzaro, NVIDIA;
(13) Arjun Chaudhuri, NVIDIA;
(14) Sharon Clay, NVIDIA;
(15) Bill Dally, NVIDIA;
(16) Laura Dang, NVIDIA;
(17) Parikshit Deshpande, NVIDIA;
(18) Siddhanth Dhodhi, NVIDIA;
(19) Sameer Halepete, NVIDIA;
(20) Eric Hill, NVIDIA;
(21) Jiashang Hu, NVIDIA;
(22) Sumit Jain, NVIDIA;
(23) Brucek Khailany, NVIDIA;
(24) George Kokai, NVIDIA;
(25) Kishor Kunal, NVIDIA;
(26) Xiaowei Li, NVIDIA;
(27) Charley Lind, NVIDIA;
(28) Hao Liu, NVIDIA;
(29) Stuart Oberman, NVIDIA;
(30) Sujeet Omar, NVIDIA;
(31) Sreedhar Pratty, NVIDIA;
(23) Jonathan Raiman, NVIDIA;
(33) Ambar Sarkar, NVIDIA;
(34) Zhengjiang Shao, NVIDIA;
(35) Hanfei Sun, NVIDIA;
(36) Pratik P Suthar, NVIDIA;
(37) Varun Tej, NVIDIA;
(38) Walker Turner, NVIDIA;
(39) Kaizhe Xu, NVIDIA;
(40) Haoxing Ren, NVIDIA.
Table of Links
- Abstract and Intro
- Dataset
- ChipNemo Domain Adaptation Methods
- LLM Applications
- Evaluations
- Discussion
- Related Works
- Conclusions
- Acknowledgments, Contributions and References
- Appendix
IV. LLM APPLICATIONS
We conducted a survey of potential LLM applications within our design teams and categorized them into four buckets: code generation, question & answer, analysis and reporting, and triage. Code generation refers to LLM generating design code, testbenches, assertions, internal tools scripts, etc.; Q & A refers to an LLM answering questions about designs, tools, infrastructures, etc.; Analysis and reporting refers to an LLM analyzing data and providing reports; triage refers to an LLM helping debug design or tool problems given logs and reports. We selected one key application from each category to study in this work, except for the triage category which we leave for further research. The motivation and technical details of each application are given below.
A. Engineering Assistant Chatbot
This application aims to help design engineers with answers to their architecture, design, verification, and build questions, which could significantly improve their overall productivity without impacting the productivity of others. It is observed that design engineers often enjoy brainstorming, designing hardware, and writing code, but can be slowed down waiting for answers on design knowledge they lack. Design productivity can also be enhanced by avoiding having engineers write code based on mistaken assumptions or debugging code that they are unfamiliar with. Internal studies have shown that up to 60% of a typical chip designer’s time is spent in debug or checklist related tasks across a range of topics including design specifications, testbench construction, architecture definition, and tools or infrastructure. Experts on these issues are often spread around the globe in a multinational company, such that it is not always convenient to find immediate help. Therefore, an engineering assistant chatbot based on knowledge extracted from internal design documents, code, any recorded data about designs and technical communications such as emails and corporate instant communications, etc. could help significantly improve design productivity. We implemented this application with the domain-adapted RAG method mentioned in Section III-D.
B. EDA Script Generation
Another common task in an industrial chip design flow is writing EDA scripts to accomplish a variety of tasks such
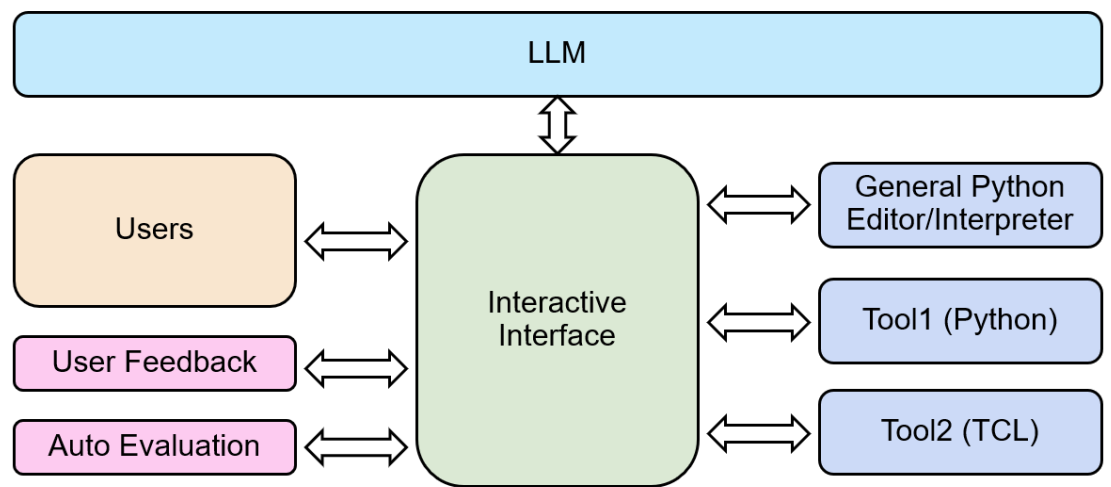
as design implementation, introspection and transformation. These scripts often leverage both tool-specific and custom internal script libraries. Learning these libraries, navigating tool documentation, and writing and debugging these scripts, can take up a significant amount of engineering time.
LLMs have proven adept at small scale code generation on a wide array of tasks [32] and therefore customizing these models to accelerate engineer productivity in this domain specific task is a natural fit. In this work we focus on generating two different types of scripts from natural language task descriptions. The first are scripts which leverage Tool1, an internal python library for design editing and analysis. The second are Tcl scripts that use the command interface provided by Tool2, which is a leading industrial static timing analysis tool.
In order to build our domain-specific fine-tuning dataset for this task, production scripts for both tools were collected from design experts. We observed that our DAPT models can generate reasonable inline comments for the code. This enabled us to use these models to improve the quality of collected scripts by generating additional inline comments. Human experts later verified and corrected these comments and created an associated prompt. These prompts and code pairs make up the data used for DSFT in the format discussed in Section III-C.
To provide and collect feedback in the most meaningful way, we spent significant effort building the flow shown in Fig. 4 where engineers can both query the model and run generated code through the same interface. This allows us to be confident in the correctness of generated code as well as provide accurate feedback by allowing engineers to see how many corrections they might need to get a functioning script. We support Tool1 and Tool2 integration by establishing interactive connections to tool servers.
Additionally, we provide a user feedback form, allowing us to compare different models and glean valuable insights from user feedback. This valuable information can aid us in further refining our models.
C. Bug Summarization and Analysis
Tracking the reporting, triage, debug and resolution of various features and bugs across stages of the production flow is a time-consuming process. Engineering managers spend a lot of time reviewing internal issue tracking databases to build understanding of the state of the project and help speed their execution. Therefore, a tool that is able to look at all supporting information and quickly summarize both technical and managerial data as well as suggest next steps would boost team productivity. We focus on using LLMs to generate three different outputs - one focused on technical details, one on managerial details and one recommending task assignment.
To study these tasks we used NVIDIA’s internal bug database, NVBugs. This database is used for bug reporting, tracking and resolution as well as general task and feature tracking across the company. We expect ChipNeMo models to perform well on this task as a large amount of bug data was included in the DAPT dataset. Additionally, we built a domain-specific SFT dataset for this task that includes examples of the bug summarizing and task assignment tasks.
Often, bug descriptions contain large snippets of log files or code dumps along with long comment histories. In such cases, the bug text is too large for our LLM context windows. To work around this, we implemented two solutions. First, we found and replaced long path names with shorter aliases to allow the model to associate paths that occur in multiple places in the bug without needing to process the entire string. Second, we split the summarization task into an incremental task where the model is tasked with accumulating data across multiple summary and bug data chunks. We use a hierarchical approach where the bug is first separated into chunks that fit into the context window. Those chunks are then summarized and the summaries are accumulated then separated into chunks. This process is repeated until the entire set of summaries fits into a single context window and a single summary is generated. We use this same approach independent of the LLM used for summarization.
This paper is available on arxiv under CC 4.0 license.