

Imagine a data scientist studying wildlife behavior, analyzing hundreds of hours of video footage from cameras in a remote forest. Or a sports coach who needs to identify key plays from an entire season's games to develop new strategies. Alternatively, consider a filmmaker searching for specific scenes within a massive video gallery to piece together a documentary.
Traditionally, all of these experts face the time-consuming, error-prone, and overwhelming challenge of manually sorting through endless hours of footage.
However, artificial intelligence and machine learning advancements have dramatically transformed video search applications. These technologies now enable us to search for specific objects and events within extensive video datasets with incredible sophistication. Data scientists and researchers can pinpoint relevant video segments with exceptional precision and efficiency.
The objective was to simplify the research process by providing advanced search capabilities, enabling users to easily locate footage with specific content or properties from extremely large video datasets.
By using sophisticated search algorithms and a user-friendly interface, OpenOrigins aimed to make the platform an important tool for this community.
OpenOrigins considered two technological approaches to building this video search offering: frame search using image embeddings and multimodal embeddings. Let’s take a look at each option.
Semantic Search Over Video Content
Enabling semantic search over video to answer complex questions such as, "How many minutes of video content are there that show deer in their natural habitat?" requires sophisticated search capabilities that can understand and interpret the content of the videos beyond basic keyword metadata matching. The key to achieving this? Multimodal embeddings.
Multimodal embedding models and multimodal large language models (LLMs) might be viewed as similar solutions. Models like CLIP and Google multimodal embeddings generate embeddings for data types such as text, images, and video, creating high-dimensional vectors that capture semantic meaning. This enables applications like semantic search, content retrieval, and similarity detection.
On the other hand, multimodal LLMs like GPT-4 (with multimodal capabilities), Flamingo, and Gemini are designed to understand and generate content across different types of data.
These models perform well with complex tasks like conversational AI and content generation by using multimodal inputs (text and images, for example) and generating multimodal outputs, resulting in meaningful and contextually rich responses.
While embedding models focus on efficient search and retrieval, multimodal LLMs are suited for generating and understanding diverse content, making them ideal for chatbots, interactive assistants, and multi-modal interactions.
|
MultiModal Embedding Models |
Multi-Modal Large Language Models (LLMs) |
|
|---|---|---|
|
Main Purpose |
Enable search and retrieval across different data modalities such as text and image |
Generate and understand content across multiple modalities |
|
Core Use Case |
Semantic search, content retrieval, and similarity |
Conversational AI, content generation, and dialogue systems |
|
Example Models |
CLIP, Google Multimodal Embedding Model |
GPT-4 (with multimodal capabilities), Llava, Gemini, Flamingo, LaMDA |
|
Search and Retrieval |
Optimized for fast, accurate search and similarity |
Optimized for comprehensive understanding and generation across different data types. |
|
Applications |
Content moderation, recommendation systems, semantic search |
Conversational agents, content creation, multi-modal interactions |
Approach 1: Frame Search With Image Embeddings
The first method that OpenOrigins looked at involved frame-by-frame analysis of videos using image embeddings. This approach breaks down the video into individual frames, each converted into a vector embedding by using
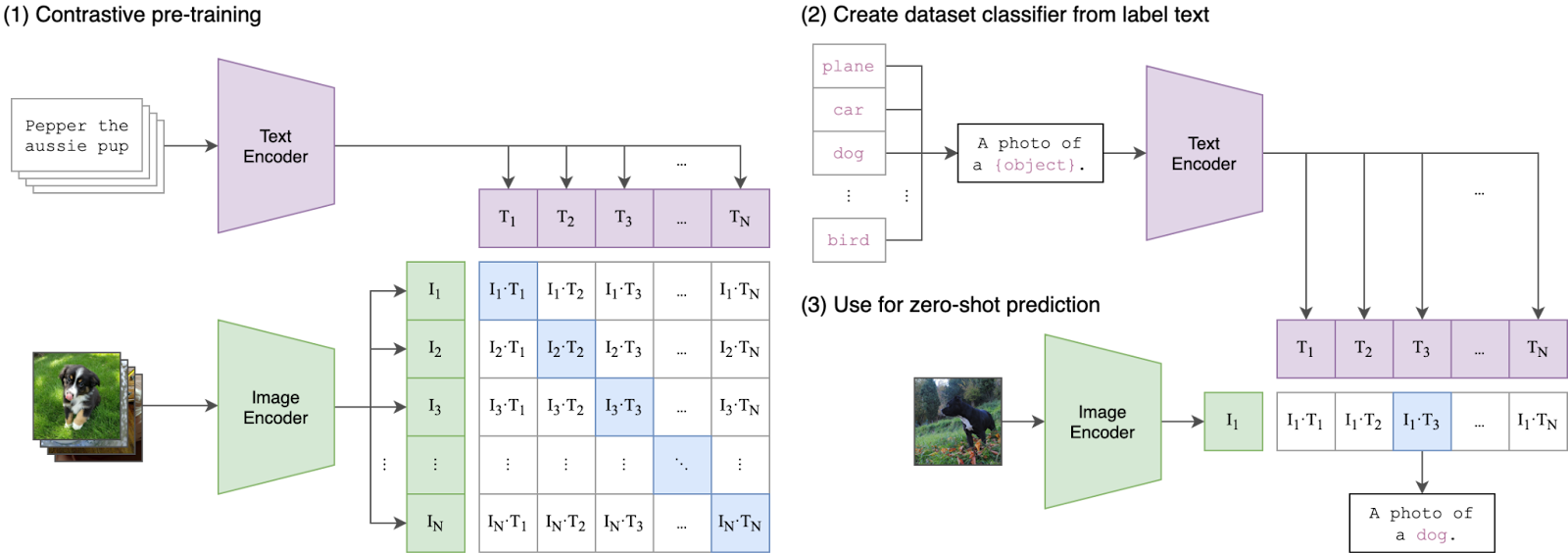
By studying millions of web images with their descriptions, CLIP comprehends visual concepts in a way that's similar to how humans perceive and describe the world. Its training involves "contrastive learning," where it learns to match images with their correct descriptions, giving it the unique ability to handle various tasks by understanding the link between what we see and the words we use.
This makes CLIP highly adaptable and useful for applications requiring a deep understanding of images and language together.
These embeddings are stored in a vector database, which enables fast and accurate searches by matching text to text, text to image, or image to image based on semantic similarity.
Frame extraction decomposes videos into frames at specified intervals. Each frame is processed through an image embedding model to generate a high-dimensional vector representation. These vectors are stored in a vector store like DataStax Astra DB, which enables efficient similarity searches.
This method offers high accuracy in multimodal semantic search and is well-suited for searching specific objects or scenes. However, it is computationally intensive, especially for long videos, and may miss temporal context or changes between frames.
Approach 2: Multi-Modal Embeddings With Google Multi-Modal Embedding Nodel
The second approach leverages the latest generative AI technology with multimodal embeddings, specifically using Google's
Google Cloud Vertex AI multimodal embeddings for video
By representing videos numerically, these embeddings enable advanced machine learning tasks, making searching, analyzing, and categorizing video content easier.
Integrating these embeddings with
Google’s multimodal embeddings and the CLIP method each embed multimodal data into a common embedding space. The main difference is that Google's multimodal embeddings support video, while CLIP doesn't.
Technical Overview
We’ve assembled the repositories below to illuminate and apply examples for both frame search video analysis and multimodal embeddings. These examples provide practical demonstrations and detailed instructions to help implement and evaluate each approach effectively.
Approach 1: Frame search with image embeddings
In this approach, we introduce a
The get_single_frame_from_scene function computes the frame ID and sets the video capture to this frame and reads it:
def get_single_frame_from_scene(scene, video_capture):
frame_id = (scene[1] - scene[0]).frame_num // 2 + scene[0].frame_num
video_capture.set(cv2.CAP_PROP_POS_FRAMES, frame_id)
_, frame = video_capture.read()
return Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
The get_frames_from_video function processes a video, detecting scenes using the AdaptiveDetector, and extracts a single frame from each scene by calling get_single_frame_from_scene, storing these frames in a list:
def get_frames_from_video(video_path):
res = []
video_capture = cv2.VideoCapture(video_path)
content_list = detect(video_path, AdaptiveDetector())
for scene in content_list:
res.append(get_single_frame_from_scene(scene, video_capture))
return res
The get_image_embedding function uses a
def get_image_embedding(image):
inputs = clip_processor(images=image, return_tensors="pt")
image_embeddings = model.get_image_features(**inputs)
return list(image_embeddings[0].detach().numpy().astype(float))
This code connects to an Astra DB database, creates a collection of JSON objects with vector embeddings, and inserts these objects into the "video" collection in the database:
import json
from astrapy import DataAPIClient
client = DataAPIClient(ASTRA_DB_TOKEN)
database = client.get_database(ASTRA_DB_API_ENDPOINT)
collectiondb = database.video
json_embedding = [
{"id": f"{i+1}", "$vector": values}
for i, values in enumerate(image_embeddings)
]
response = collectiondb.insert_many(json_embedding)
Search for a certain text by using OpenAI Clip embeddings:
query_text = "men with white hair"
query_embedding = get_text_embedding(query_text)
result = collectiondb.find_one({}, vector=query_embedding)
Approach 2: Multi-modal embeddings with Google multi-modal embedding model
Here, you can see how to create video embeddings using Google's multimodal embedding model and store them in Astra DB, including metadata information such as start_offset_sec and end_offset_sec (check out the
import vertexai
from vertexai.vision_models import MultiModalEmbeddingModel, Video
from astrapy import DataAPIClient
import streamlit as st
# Initialize Vertex AI
vertexai.init(project=st.secrets['PROJECT'], location=st.secrets['REGION'])
# Initialize the client
client = DataAPIClient(st.secrets['ASTRA_TOKEN'])
database = client.get_database(st.secrets['ASTRA_API_ENDPOINT'])
my_collection = database.create_collection(
"videosearch",
dimension=1408,
metric=astrapy.constants.VectorMetric.COSINE,
)
collectiondb = database.videosearch
# Load the pre-trained model and video
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
video = Video.load_from_file(st.secrets['PATH'])
# Get embeddings with the specified contextual text
embeddings = model.get_embeddings(
video=video,
contextual_text="Mixed Content",
dimension=1408,
)
# Video Embeddings are segmented based on the video_segment_config.
for video_embedding in embeddings.video_embeddings:
# Check if embedding is a numpy array or a tensor and convert accordingly
if isinstance(video_embedding.embedding, (list, tuple)):
embedding_list = video_embedding.embedding
else:
embedding_list = video_embedding.embedding.tolist()
embedding_data = {
"metadata": {
"start_offset_sec": video_embedding.start_offset_sec,
"end_offset_sec": video_embedding.end_offset_sec
},
"$vector": embedding_list # Ensure embedding is in list format
}
response = collectiondb.insert_one(embedding_data)
Here, we set up the
import vertexai
from vertexai.vision_models import MultiModalEmbeddingModel, Video
from vertexai.vision_models import Image as img
from astrapy import DataAPIClient
import streamlit as st
from PIL import Image
st.title("Video Search App")
user_input_placeholder = st.empty()
user_input = user_input_placeholder.text_input(
"Describe the content you're looking for:", key="user_input"
)
uploaded_file = st.file_uploader("Choose an image file that is similar you're looking for", type="png")
if uploaded_file is not None:
image = Image.open(uploaded_file)
image_path = st.secrets['IMAGE_PATH']
image.save(image_path)
saved_image = Image.open(image_path)
st.image(saved_image, caption='', use_column_width=True)
# Initialize Vertex AI
vertexai.init(project=st.secrets['PROJECT'], location=st.secrets['REGION'])
# Initialize the client
client = DataAPIClient(st.secrets['ASTRA_TOKEN'])
database = client.get_database(st.secrets['ASTRA_API_ENDPOINT'])
collectiondb = database.videosearch
# Load the pre-trained model and video
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
video = Video.load_from_file(st.secrets['PATH'])
# Search action trigger
if st.button("Search"):
if user_input:
embeddings = model.get_embeddings(
contextual_text=user_input
)
result = collectiondb.find_one({}, vector=embeddings.text_embedding)
start_offset_value = result['metadata']['start_offset_sec']
end_offset_value = result['metadata']['end_offset_sec']
st.write("Text input result found between: " + str(start_offset_value) + "-" + str(end_offset_value))
video_file = open(st.secrets['PATH'], 'rb')
video_bytes = video_file.read()
st.video(video_bytes, start_time=start_offset_value)
if uploaded_file is not None:
embimage = img.load_from_file(image_path)
embeddingsimg = model.get_embeddings(
image=embimage
)
imgresult = collectiondb.find_one({}, vector=embeddingsimg.image_embedding)
start_offset_value = imgresult['metadata']['start_offset_sec']
end_offset_value = imgresult['metadata']['end_offset_sec']
st.write("Image input result found between: " + str(start_offset_value) + "-" + str(end_offset_value))
video_file = open(st.secrets['PATH'], 'rb')
video_bytes = video_file.read()
st.video(video_bytes, start_time=start_offset_value)
Here’s what the results look like:
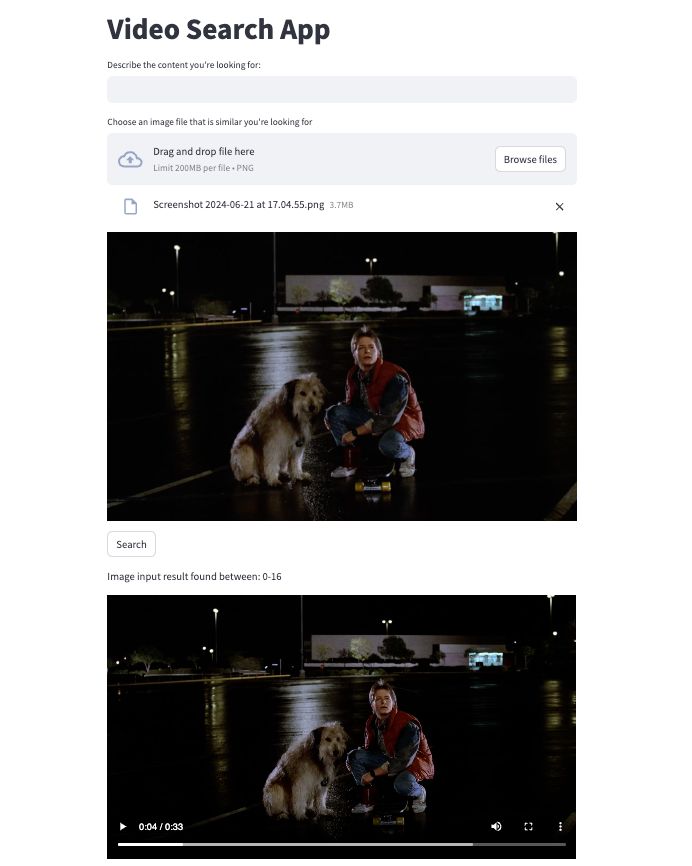
Conclusion
Exploring these two approaches highlights the significant potential of modern AI techniques in video search applications. While frame search with image embeddings provides high accuracy for specific visual searches, the flexibility and power of multimodal embeddings make them a superior choice for complex, multimodal search requirements.

By using Astra DB, a video search platform can provide users with advanced search capabilities, enabling precise and efficient retrieval of specific video content from large datasets. This significantly improves the ability to analyze and interpret video data, leading to faster and more accurate insights.
Looking ahead, the future of video search is bright with ongoing research and development. Advances in AI and machine learning will continue to improve these techniques, making them more accessible and efficient. Integration with other emerging technologies, such as augmented reality and real-time video analysis, will further expand their capabilities.
By Matthew Pendlebury, Head of Engineering, OpenOrigins, and Betul O’Reilly, Solutions Architect, DataStax